
What is a Content Database?
Adding context to build smarter apps and content creations.
To describe a Content Database, it helps to first define Content:
Content = Data + Context
Content is application data with relevant context. For example, if the application data is a web page, then its context may be who last edited it, and whether the update has been approved by site stakeholders. Or, it may have variants based on the local language it is to be displayed in or which market segment it is intended to target. Context can mean a lot of things, but above all it's the meta information surrounding the data serving an application.
A traditional database stores data and does this well; it provides a foundation for storing rows and columns, is performant with large numbers of rows, and provides ACID transaction support and other low-level row manipulation features.
A content database builds on a traditional database by providing common context features that web, mobile, and other software applications need to build new solutions efficiently.
In short:
A Content Database provides all of the tools and features needed to make building and supporting content-driven applications quicker and easier.
webCOMAND implements a content database and many of the features described here. Below we describe some types of content contexts that are common in all web applications today. You can also download the slides we used when giving a talk on these features. Future posts in this series will dive into how our open source API implements some of these features in more detail.
Organization
It is useful for both developers and content creators to organize content into groups, folders and hierarchies. Data supporting large web applications can be impossible for clients to manage without some sort of visual hierarchy, and for developers a clear organizational structure can help keep software maintenance costs down.
While it is possible to model and query hierarchies in a traditional database, it can be tricky to do efficiently (see Hierarchical Data in SQL). A content database will abstract away this complexity and make creating folders, and querying based on them, simple for developers and end-users. A content database with a built-in concept of folders can also leverage these when exposing other features like folder-based authorizations, which are not available in traditional databases.
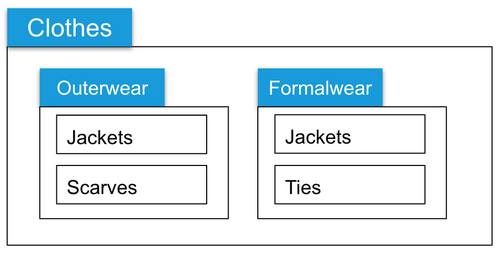
Organization: Product inventory in an e-commerce solution, organized by product type and subtype.
Inheritance
Developers are familiar with principles of object-oriented programming and the value of inheritance. Inheritance is the ability to reuse and specialize properties and behaviors of other objects or classes within a system. Using principles of inheritance in software design saves time and money by eliminating the error-prone duplication of logic in a program.
This concept applies well to content libraries as well. For example, in an e-commerce product catalog, all products typically share a common set of fields, like Title, SKU and Price. However, individual products may need to extend those fields to include fields specific to the product type, like Size and Color for clothing, or Make and Model for appliances. Inheritance provides an efficient way to model and query shared and type-specific fields, and a content database will enable types to be extended and queried against without extra work for the developer.
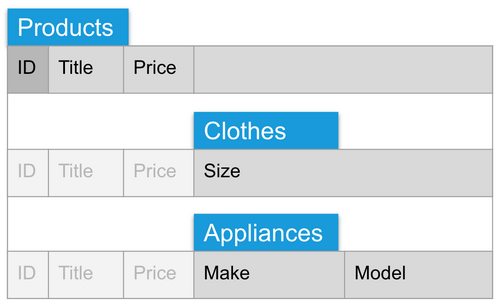
Inheritance: Products with sub-products 'Clothes' and 'Appliances' that add custom fields.
Authorizations
Traditional databases do provide an authorization model, granting specific privileges on tables to database users. However, because these databases don't have any type of organizational structure beyond tables and columns, it is impossible to impose more fine-grained authorizations that web applications often need.
For example, a web application for an inventory system may want some users to be able to add or remove products for one department, but not others. Other users may be only be authorized to change inventory counts, but not alter other project information. Developers creating this application on a traditional database would have to implement these roles on a custom basis. A content database, on the other hand, would leverage its organization structure to implement folder-based and field-based roles out of the box. The developer would only need to define the roles their end-users need, saving considerable time in the implementation process.
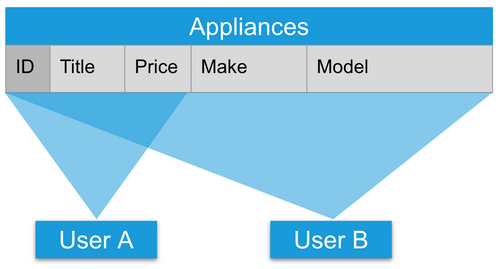
Authorization: Users have access to different fields of a product depending on their assigned roles.
Workflow
Content is consciously authored, so it requires a structured development process with different phases and touch points, so the concept of workflow is critical. In other words, a content database needs to track what stage in the editorial process the content is in. For example, content might start out as a working copy where authors collaborate on it, similar to Google Docs. Then, at some point a draft will be saved for editorial review and edits. Finally, the content is ultimately approved for release production (public websites, apps and/or print publications).
Further, it is common for content to exist in multiple stages at the same time, like when a content author is changing a working copy and saving drafts while an approved version remains in production. Only once a final draft is approved does the new version move into production.
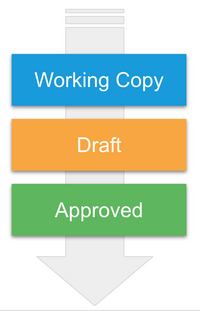
Workflow: Users can collaborate on a working copy, save drafts to review in a testing environment, and approve content for publication or syndication.
Revisions
It is also important to keep a history of revisions for reference, comparison and rollback or undo. History for individual records can be critical for sensitive information, keeping a clear record of who has made changes and why. Medical records are a good example of this, and traditional databases often do not support this out of the box.
Sometimes even per-record history is not enough, and web applications need to be able to query against the entire content repository for a particular date and time. For example, a long-running process may need to operate on a point-in-time snapshot of the repository without freezing the system from edits, or end users may want to review the state of the repository at a particular point without the costly baggage of complete backups. These features, when enabled out of the box, allow developers to add a lot of value for their end-clients with little work on the implementation-side.
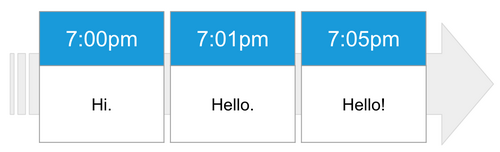
Revisions: Content captures versions of content as it is approved, so it can be archived or reviewed later.
Variants
Because traditional databases store data in rows and columns, this one-dimensional representation does not lend itself well to content variants. Variants are different versions of the same content, which is extremely common in web applications today. For example, content may be translated into many different languages depending on where it is being served. Those language variants may themselves have their own variants, such as serving different market segments or site users (i.e. "Pleased to meet you" versus "Welcome back"). A content database will avail these capabilities to content creators out of the box and simplify the logic for querying these variants for developers.
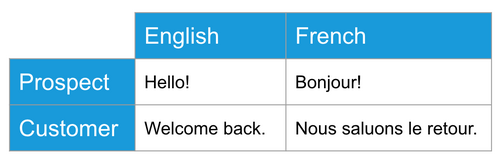
Variants: The same content can be represented in different languages, for different users, or other types of variations.
Contextual Queries
A content database, once it implements the above features, must make them easy to access and control. A traditional database will enable data to be managed and queried through a query language like SQL. A content database, in addition to tracking context for its data, should allow users to query for their content in a way that lets them include the context as well. For example, it should be simple to query for content in a particular language or other variant, or to query against workflow state or versions of data at a particular date and time.
Sometimes it makes sense to specify aspects of a context for a "query session" or set of queries. Other times, it may be necessary to specify aspects per-query. A content database that exposes these context features in this way is a very powerful tool for developers that are creating content-based applications.
Implementation
webCOMAND implements all of these features, including contextual query languages: cQL, cPath and cQuery. If you don't already have an account, sign up free.
And in true open source spirit, our next blog post will cover how each of these features are implemented in webCOMAND, including existing and potential future optimizations.
Cover Photo by Skye Studios on Unsplash
More Posts
